TIL: Convolutional Filters Are Weights
It’s common knowledge that there’re weights in a fully-connected neural network. And these weights are not constant and are adjusted by an optimization algorithm (like gradient descent). Moreover, training a neural network actually means finding proper weights.
When I started learning about convolution and convolutional networks, first thing I was introduced to is filters. Filters are said to be matrices that are applied to an image to distort it in a certain way, unveiling certain aspect of an image. For example, applying a filter to an image can unveil its contour edges:
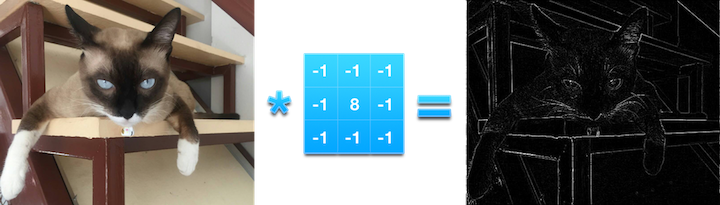 (this example is created via http://setosa.io/ev/image-kernels/)
(this example is created via http://setosa.io/ev/image-kernels/)
Then I started trying running different examples of convolution networks and noticed that I never decided what filters I wanted to use in a network. I thought that people somehow find proper filter manually, but now the truth has finally revealed: filters are weights. And they’re adjusted while network is trained.
Isn’t this marvelous? A convolutional neural network learns to “see” something that makes the whole network produce better results.
Initially, filters are often initialized randomly, so network “sees” random stuff. But, after more and more iterations are passed, network learns to “see” such aspects of image that make the whole network give better results.
To demonstrate this, I took this mnist_cnn.py example from Keras and visualized the filters of the first convolutional layer three times:
- After training the network for 1 iteration.
- After training the network for 7 iterations.
- And after training the network for 15 iterations.
Here’re the visualisations:

These images make no sense for a human, but it’s these filters that allow the whole network to correctly recognize hand digits.